The correct answer is "who cares" though. Languages which use cased alphabets.. use cased alphabets, you don't get to argue with it.
You also don't get to argue with the fusional position changes in Arabic, or the ligatures in Devanagari, or the places within a square the featural particles of Hangul must be printed in.
You are correct that its not negotiable when supporting that language, but it is negotiable what languages and writing sets a given application support.
I think you have correctly identified an implausible claim!
Of course, most languages aren't written at all ... or at least don't have a traditional written form that is sufficiently well established for someone to say that the "language" has case rather than a particular (proposed) way of writing it.
However, I rather suspect that the majority of languages in which books are published use some variant of the Latin alphabet and do, therefore, have case. (The only language I've heard of that uses the Latin alphabet without case is Lojban!)
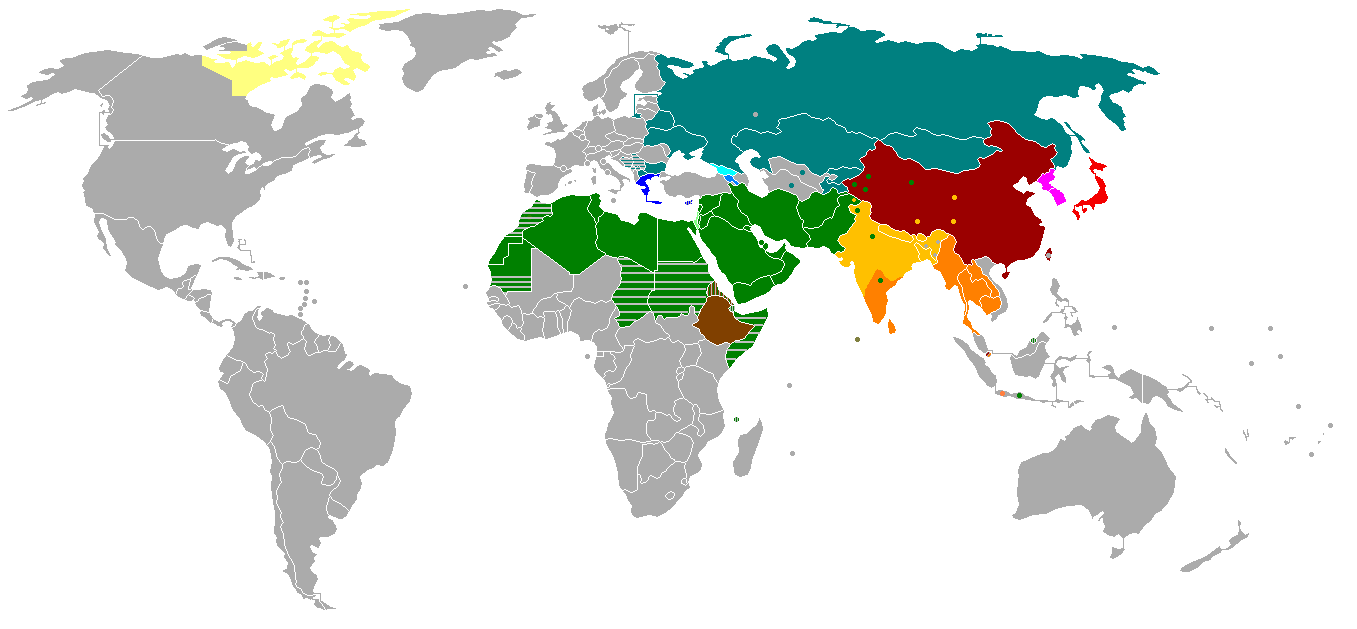
On the other hand, if you weight languages by the number of (native) speakers, since about three quarters of the world's population lives in China, India, Pakistan, Bangladesh, Japan or Korea, probably it's true that most people don't use case in their main language.
It's just blown my mind that case might be a thing non-English speakers would need to learn to be able to read and write English. (Same for non-English, but that doesn't blow my mind in the same way.)
Yeah, we always say that the English alphabet has 26 letters, but there are actually 52 unique symbols you have to learn to read, or 104 if you also have to read/write cursive. Some of these symbols are very similar (if you learn 'o' you will definitely recognize 'O', and likely the cursive variants as well), while others are quite different ('g', 'G', and the cursive upper case G might as well be different letters altogether; the lower-case cursive does resemble 'g').
With joined-up letters (“cursive” in the USA I guess) different languages have different letterforms, and sometimes multiple systems.
For that matter typesetting rules vary by language as well — not just the obvious hyphenation rules busnspacimg as well. Just pick up a book in, say, French or Russian and you can tell at a glance (without even looking at the letters) that it’s not in English.
Right, 104 symbols would be the minimum if you do need to read/write cursive.
However, I don't agree with your point about typeset text. You're right that the styles differ, but if you have learned one style, and know the language of the text, you will not need any significant amount of time to read a different style of typesetting.
Russian of course normally uses the Cyrillic alphabet, not the Latin one, so obviously you do have to learn a whole new set of symbols to understand it even if you can read Latin symbols. And of course French uses slightly more letters/letter forms than English, with the sedile and four accents (egu, grave, circonflex, and very rare treme).
Lots of accents when using Cyrillic to write non-Russian text.
I didn’t mean the typesetting differences made reading a different language in any way hard, merely pointing out that there are lots of different aspects to text in different languages even when the alphabets are basically the same.
And there are a fair number of (inconsistent) rules for casing. Proper nouns vs. common nouns. Camel case (or other non-standard capitalizations). Title case. "Standard" body copy.
Are they a majority of languages if counted? I guess it also matters if you count the number of languages or if you count the number of people writing them.
Let’s just use Greek and its descendants (Latin, Greek and cyrillic alphabets) and Brahmic-derived writing (we said “alphabet” when I was a kid but now ppl say “ Abugida“. There are about 200 languages spoken in Europe, all of which use these alphabets. India has over a hundred “major” languages and about 1600 others, most of which use Bramic writing alphabets (the major exception, Urdu, uses a form of Arabic writing). So a big imbalance!
Oh, you want speakers? merely counting people who read Hanzi + Arabic-Alphabet readers + the Indian subcontinent gets you more half the world‘s population. And there are hundreds, maybe over a thousand writing systems.
When we sum up realistically, then world-wide the amount of users of writing systems with case/"cameral" are about equally balanced with those without.
{kind=link}